Note
Go to the end to download the full example code.
Benchmark of Error-Free Transforms for dot product#
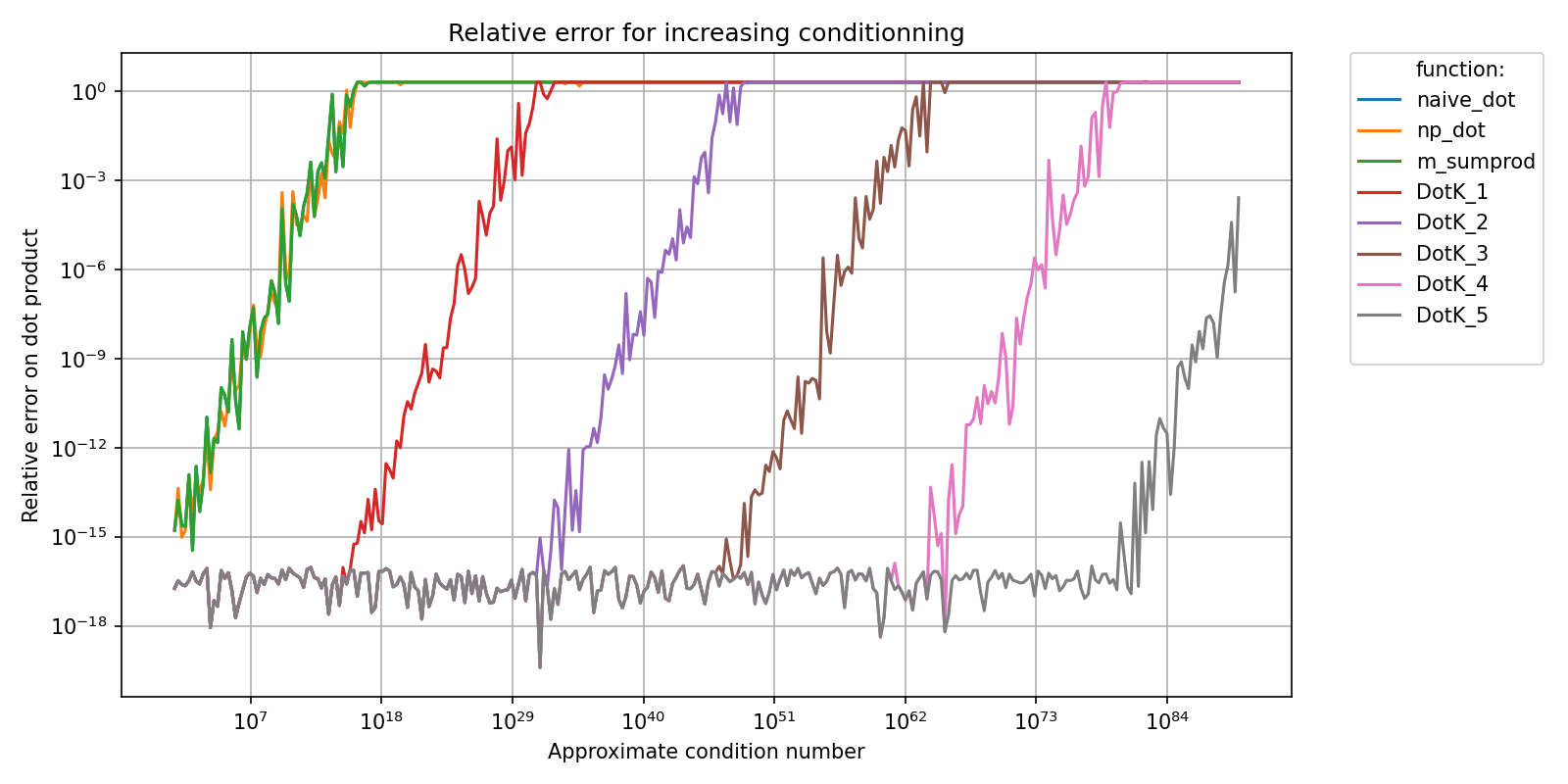
This benchmark compares the accuracy and efficiency of several dot product algorithms in floating point arithmetics.
def naive_dot(x, y):
return choreo.segm.cython.eft_lib.naive_dot(x,y)
def naive_dot_ptr(x, y):
return choreo.segm.cython.eft_lib.naive_dot_ptr(x,y)
def np_dot(x, y):
return np.dot(x,y)
def m_sumprod(x, y):
return m.sumprod(x, y)
def DotK_1(x, y):
return choreo.segm.cython.eft_lib.DotK(x,y,1)
def DotK_2(x, y):
return choreo.segm.cython.eft_lib.DotK(x,y,2)
def DotK_3(x, y):
return choreo.segm.cython.eft_lib.DotK(x,y,3)
def DotK_4(x, y):
return choreo.segm.cython.eft_lib.DotK(x,y,4)
def DotK_5(x, y):
return choreo.segm.cython.eft_lib.DotK(x,y,5)
def prepare_x(n):
x = np.random.random(n)
y = np.random.random(n)
return {'x': x, 'y': y}
pyquickbench.plot_benchmark(
all_times ,
all_sizes ,
all_funs ,
show = True ,
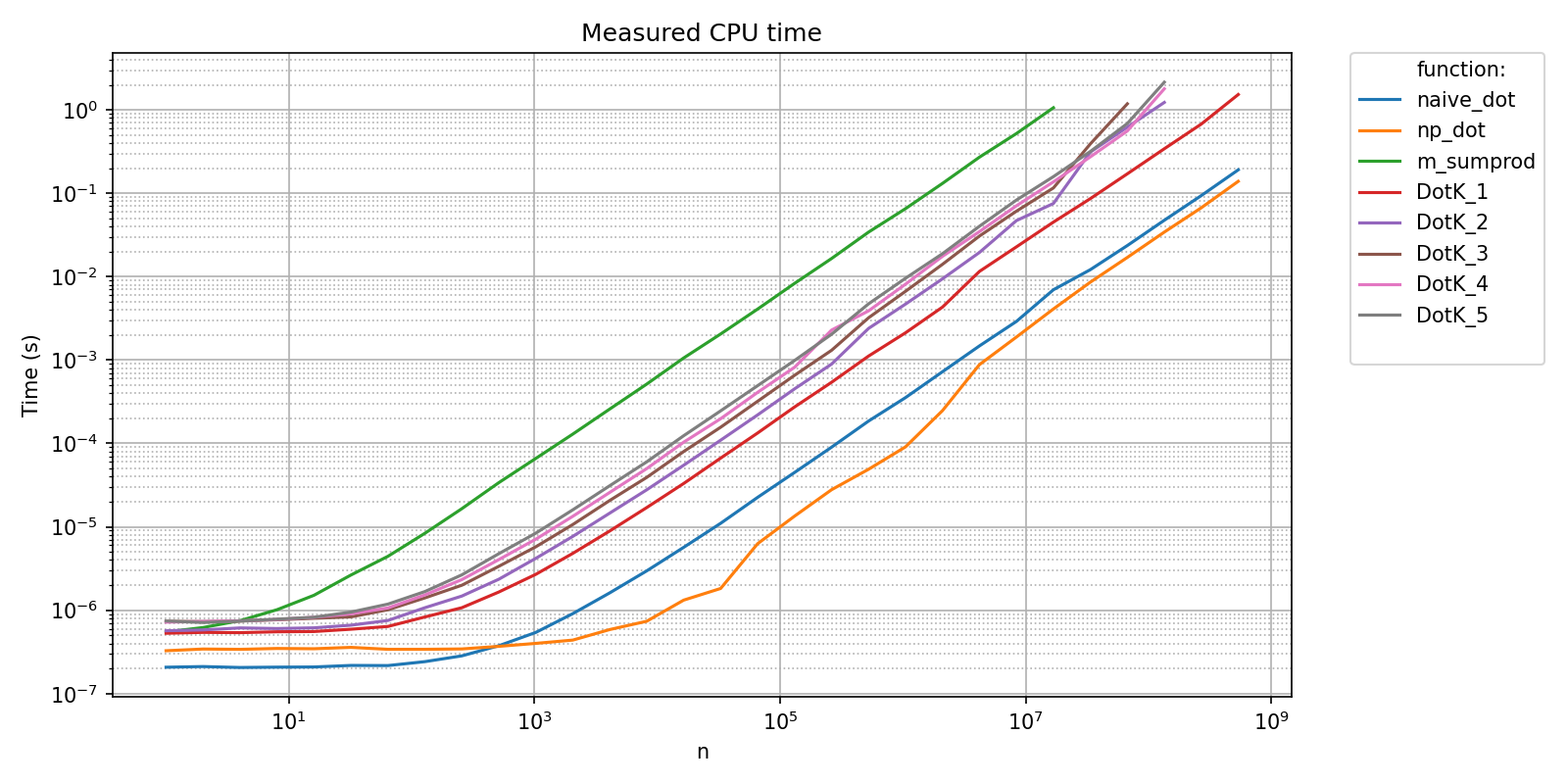
title = "Measured CPU time" ,
)
pyquickbench.plot_benchmark(
all_times ,
all_sizes ,
all_funs ,
show = True ,
relative_to_val = {pyquickbench.fun_ax_name: "naive_dot"},
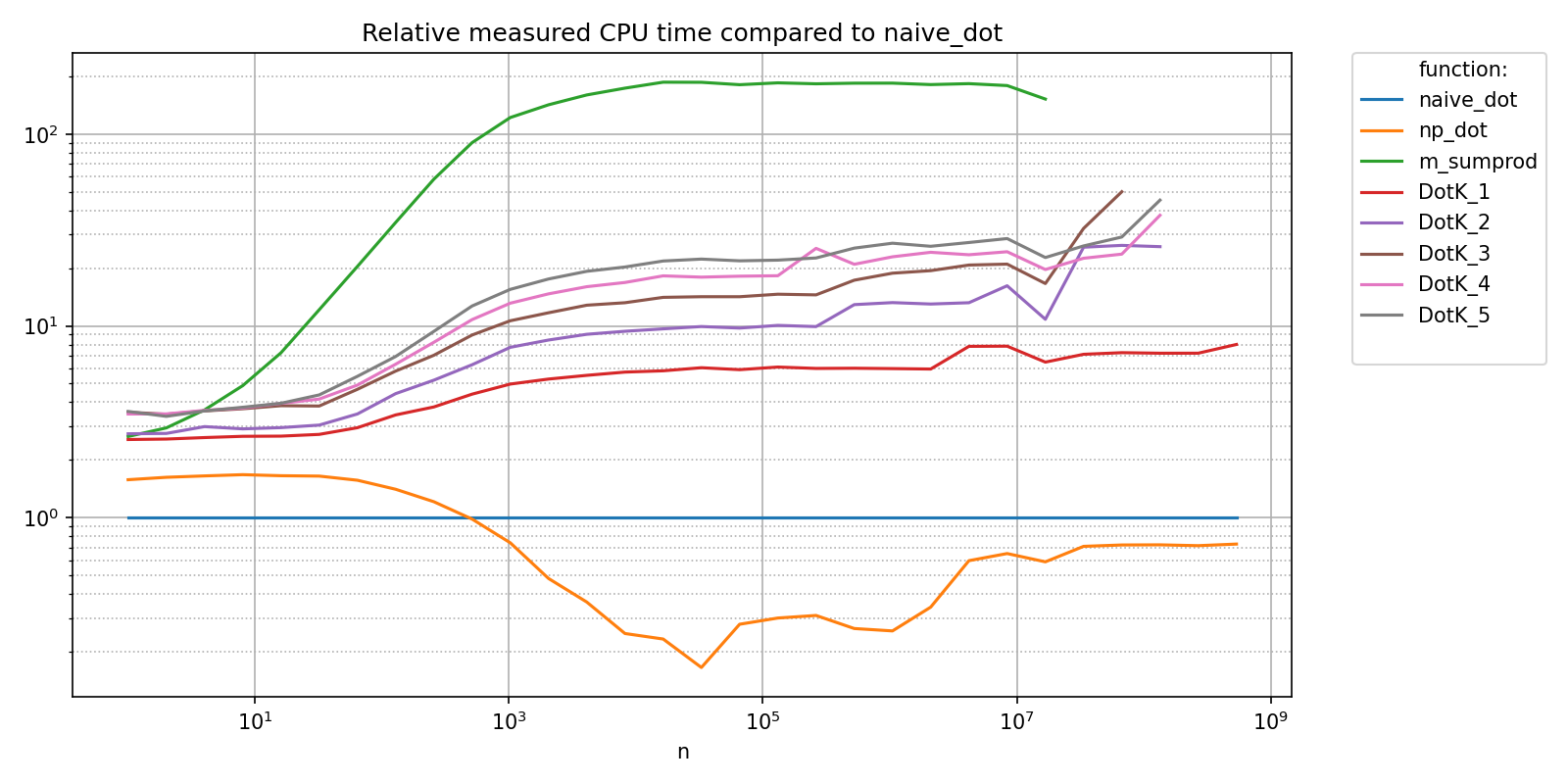
title = "Relative measured CPU time compared to naive_dot" ,
)